La librairie Simple Data Analysis
Les sous-titres sont disponibles en français.Dans cette leçon, nous allons apprendre à utiliser la librairie en code ouvert que j’ai créée : simple-data-analysis. Nous analyserons des données historiques de température moyenne quotidienne dans trois villes canadiennes à titre d’exemple. Notre objectif sera de répondre à cette question :
- À quelle vitesse les températures ont-elles augmenté ces dernières décennies ?
Pour ce faire, nous calculerons la température moyenne par période de 30 ans et examinerons les tendances.
Si vous avez une minute, ajoutez un ⭐ à la page GitHub de la librairie. C’est toujours agréable de savoir que son travail en code ouvert est apprécié. 😊
Notez que je m’attends à ce que vous ayez au moins complété les sections Premiers pas 🧑🎓 et Aller plus loin 🚀.
Installation
La librairie est publiée sur JSR, et vous pouvez l’installer en exécutant deno add jsr:@nshiab/simple-data-analysis.
Mais il y a une meilleure façon. 😏
Créez un nouveau dossier sur votre ordinateur et exécutez plutôt cette commande : deno -A jsr:@nshiab/setup-sda
Cela indique à Deno d’exécuter une autre librairie appelée setup-sda, que j’ai également créée pour installer et configurer facilement tout ce dont vous avez besoin pour démarrer une nouvelle analyse de données.
Après avoir exécuté la commande, votre terminal affichera une description des fichiers créés et des librairies installées.

Pour que SDA fonctionne correctement, il est recommandé d’avoir au moins la version 2.1.9 de Deno. Pour vérifier votre version, vous pouvez exécuter deno --version dans votre terminal. Pour la mettre à jour, il suffit d’exécuter deno upgrade.
Fichiers créés
deno.json: Si vous l’ouvrez, vous verrez deux tâches. Nous utiliseronssdapour surveiller, vérifier et exécutersda/main.ts. Vous verrez également trois librairies listées. Plus d’informations ci-dessous..gitignore: Un fichier important lors de l’utilisation degitpour sauvegarder notre code. Ne vous en souciez pas pour l’instant ; il y aura une leçon complète à ce sujet.sda/main.ts: Le fichier principal de notre script. C’est ici que nous écrirons notre code.sda/helpers: Un dossier vide pour le moment, mais vous pourrez l’utiliser pour vos fonctions.sda/data: Un dossier vide pour le moment, mais c’est ici que nous stockerons nos données pour l’analyse.sda/output: Un dossier vide pour le moment. C’est ici que nous écrirons nos résultats dans des fichiers.README.md: Un fichier texte contenant quelques informations sur le projet, que vous pouvez modifier comme bon vous semble.
Librairies installées
simple-data-analysis: La librairie que nous utiliserons pour traiter les données.journalism: Une autre librairie que j’ai créée. Elle contient des fonctions utiles pour diverses tâches, comme le formatage des dates ou l’envoi de données vers Google Sheets.@observablehq/plot: Une librairie créée par Mike Bostock (créateur de d3.js) que nous utiliserons pour créer des graphiques et des cartes.
Maintenant que vous savez ce qu’il y a dans votre dossier, passons au travail. Exécutez la tâche suggérée pour exécuter et surveiller notre code : deno task sda
Création d’une table
Laissez-moi vous expliquer le code actuel dans ./sda/main.ts.
Lorsque vous utilisez SDA, vous créez une base de données en mémoire. C’est ce qui se passe à la ligne 3 avec const sdb = new SimpleDB(). Une fois nos calculs terminés, nous fermons la base de données à la ligne 7 avec await sdb.done().
import { SimpleDB } from "@nshiab/simple-data-analysis";
const sdb = new SimpleDB();
// Do your magic here!
await sdb.done();Comme dans une base de données classique, avec SimpleDB, les données sont stockées dans des tables. Si vous êtes plus familier avec Excel ou Google Sheets, les tables peuvent être comprises comme des onglets.
Créons-en une pour stocker les températures quotidiennes.
Pour créer une table, vous pouvez utiliser la méthode .newTable(). Vous pouvez lui donner un nom (bien que ce soit optionnel) et stocker la table dans une variable. En général, je nomme la variable et la table de la même façon.
import { SimpleDB } from "@nshiab/simple-data-analysis";
const sdb = new SimpleDB();
const temperatures = sdb.newTable("temperatures");
await sdb.done();Maintenant que nous avons une table, nous pouvons utiliser les méthodes de la table ! Sur une nouvelle ligne, tapez la variable temperature (qui fait maintenant référence à la table) et ajoutez un . immédiatement après pour voir toutes les méthodes disponibles. Vous pouvez utiliser les flèches haut et bas de votre clavier pour consulter leur documentation et leurs exemples. Il y en a beaucoup !
Toutes les méthodes documentées avec des exemples sont également disponibles sur JSR.
Dans la capture d’écran ci-dessous, je me suis arrêté sur loadData, qui est la méthode que nous allons utiliser dans un instant.

Chargement des données
J’ai téléversé les températures quotidiennes historiques de trois villes canadiennes sur GitHub. C’est un fichier CSV que vous pouvez voir ici. Il provient des Données climatiques canadiennes ajustées et homogénéisées d’Environnement Canada.
Utilisons la méthode loadData pour le récupérer. Notez que cette méthode peut aussi bien récupérer des fichiers distants que lire des fichiers locaux. Elle peut charger des fichiers CSV, JSON, Excel et Parquet. Plutôt pratique !
Ce serait intéressant de voir les données une fois chargées. Nous pouvons le faire en appelant la méthode logTable.
Toutes les méthodes des tables sont async, nous devons donc spécifier await devant elles.
import { SimpleDB } from "@nshiab/simple-data-analysis";
const sdb = new SimpleDB();
const temperatures = sdb.newTable("temperatures");
await temperatures.loadData(
"https://raw.githubusercontent.com/nshiab/simple-data-analysis/refs/heads/main/test/data/files/dailyTemperatures.csv",
);
await temperatures.logTable();
await sdb.done();Et voici le résultat ! Nous pouvons voir que les données du fichier CSV ont été intégrées dans la table temperature, qui contient désormais trois colonnes et 131 192 lignes.

Assembler des tables
Ce serait mieux de remplacer les identifiants (id) par les noms des villes. Les identifiants et les noms des villes se trouvent dans un autre fichier que j’ai également téléversé sur GitHub.
Allons le récupérer aussi.
import { SimpleDB } from "@nshiab/simple-data-analysis";
const sdb = new SimpleDB();
const temperatures = sdb.newTable("temperatures");
await temperatures.loadData(
"https://raw.githubusercontent.com/nshiab/simple-data-analysis/refs/heads/main/test/data/files/dailyTemperatures.csv",
);
await temperatures.logTable();
const cities = sdb.newTable("cities");
await cities.loadData(
"https://raw.githubusercontent.com/nshiab/simple-data-analysis/refs/heads/main/test/data/files/cities.csv",
);
await cities.logTable();
await sdb.done();
Maintenant, nous voulons intégrer les noms des villes dans la table temperature. Pour cela, nous pouvons utiliser la méthode .join().
Par défaut, cette méthode recherche une colonne commune dans deux tables et associe les lignes en fonction des valeurs de cette colonne.
Ainsi, lorsque nous écrivons await temperature.join(cities), nous demandons à SDA de trouver une colonne commune (qui est id) dans temperature et cities, puis d’ajouter les valeurs de cities correspondant au même id aux lignes correspondantes dans temperature.
Notez que j’ai mis en commentaire les appels précédents à logTable aux lignes 9 et 15 pour éviter de surcharger le terminal.
import { SimpleDB } from "@nshiab/simple-data-analysis";
const sdb = new SimpleDB();
const temperatures = sdb.newTable("temperatures");
await temperatures.loadData(
"https://raw.githubusercontent.com/nshiab/simple-data-analysis/refs/heads/main/test/data/files/dailyTemperatures.csv",
);
// await temperatures.logTable();
const cities = sdb.newTable("cities");
await cities.loadData(
"https://raw.githubusercontent.com/nshiab/simple-data-analysis/refs/heads/main/test/data/files/cities.csv",
);
// await cities.logTable();
await temperatures.join(cities);
await temperatures.logTable();
await sdb.done();Et maintenant, nous avons les noms des villes dans la table temperature !

Mise en cache
Actuellement, à chaque fois que nous enregistrons main.ts, les deux fichiers CSV sont téléchargés à nouveau à partir de GitHub. Cela est lent et inutile puisque les données ne changent pas.
Mettons tout ce que nous avons fait jusqu’à présent en cache avec la méthode .cache().
Vous pouvez encapsuler votre code dans une fonction async et la passer à .cache(). La première fois que ce code s’exécute, SDA récupérera les données et effectuera les calculs nécessaires avant d’écrire les résultats dans le dossier .sda-cache.
Ici, j’ai défini l’option cacheVerbose à true lors de l’instanciation de SimpleDB afin d’afficher les informations liées au cache dans le terminal.
import { SimpleDB } from "@nshiab/simple-data-analysis";
const sdb = new SimpleDB({ cacheVerbose: true });
const temperatures = sdb.newTable("temperatures");
await temperatures.cache(async () => {
await temperatures.loadData(
"https://raw.githubusercontent.com/nshiab/simple-data-analysis/refs/heads/main/test/data/files/dailyTemperatures.csv",
);
// await temperatures.logTable();
const cities = sdb.newTable("cities");
await cities.loadData(
"https://raw.githubusercontent.com/nshiab/simple-data-analysis/refs/heads/main/test/data/files/cities.csv",
);
// await cities.logTable();
await temperatures.join(cities);
});
await temperatures.logTable();
await sdb.done();Voici le résultat lors de la première exécution.
Comme indiqué dans le terminal, SDA n’a rien trouvé en cache pour le code entre les lignes 8 et 19, donc il a tout exécuté. Cela a pris 1 sec, 441 ms avec ma connexion Internet et mon ordinateur. Le dossier .sda-cache a été créé, et les données y sont maintenant mises en cache.

Quand j’enregistre main.ts à nouveau (CMD + S sur Mac et CTRL + S sur PC), le comportement change.
SDA vérifie si le code entre les lignes 8 et 19 a été modifié. Comme il est exactement le même, SDA charge simplement les résultats de l’exécution précédente stockés dans .sda-cache.
Au lieu de 1 sec, 441 ms, l’exécution du script n’a pris que… 32 ms ! C’est 45 fois plus rapide ! 😱
Ici, la majeure partie du temps gagné provient de la récupération des données qui se fait par le Web. Mais comme nous le verrons dans d’autres leçons, vous pouvez également mettre en cache les résultats de calculs lourds qui prennent du temps à s’exécuter, ce qui peut améliorer considérablement votre productivité.

Lorsque vous utilisez la méthode .cache(), il est très important d’appeler await sdb.done() à la fin de votre script. Entre autres, cette méthode supprime les données en cache non utilisées à chaque exécution. Sans cela, le cache pourrait devenir très volumineux. Et si vous voulez nettoyer votre cache manuellement, exécutez simplement deno task clean.
Explorer les données
Pour explorer les données, nous pouvons utiliser la méthode .summarize(). Elle agrège les données contenues dans la table.
Commençons par time. Nous spécifions categories comme étant les valeurs de la colonne city pour voir les détails pour chaque ville.
import { SimpleDB } from "@nshiab/simple-data-analysis";
const sdb = new SimpleDB({ cacheVerbose: true });
const temperatures = sdb.newTable("temperatures");
await temperatures.cache(async () => {
await temperatures.loadData(
"https://raw.githubusercontent.com/nshiab/simple-data-analysis/refs/heads/main/test/data/files/dailyTemperatures.csv",
);
// await temperatures.logTable();
const cities = sdb.newTable("cities");
await cities.loadData(
"https://raw.githubusercontent.com/nshiab/simple-data-analysis/refs/heads/main/test/data/files/cities.csv",
);
// await cities.logTable();
await temperatures.join(cities);
});
await temperatures.summarize({
values: "time",
categories: "city"
});
await temperatures.logTable();
await sdb.done();Les valeurs min et max montrent que nous avons plus d’un siècle de températures quotidiennes pour nos trois villes. C’est plutôt bien pour analyser les tendances !
Mais il y a un problème… La colonne count affiche des valeurs différentes pour chaque ville. Théoriquement, nous devrions avoir environ 44 195 jours en 121 ans. Nous en voyons moins ici, ce qui signifie que nous allons devoir gérer des données manquantes…

Si l’affichage de la table semble étrange dans votre terminal, c’est parce que la largeur de la table est plus grande que celle de votre terminal. Faites un clic droit sur le terminal et cherchez Toggle size with content width. Il existe aussi un raccourci très pratique que j’utilise tout le temps pour cela : OPTION + Z sur Mac et ALT + Z sur PC.
Voyons maintenant ce que nous avons dans t, qui représente la température. Il suffit de remplacer "time" par "t" à la ligne 23.
Hmm… Non seulement nous avons des lignes manquantes dans nos données, comme nous l’avons vu juste au-dessus, mais nous avons aussi certaines lignes avec des valeurs null.

Occupons-nous de ce problème immédiatement en utilisant la méthode .removeMissing(). Elle supprime toutes les lignes contenant une valeur null. Vous pouvez aussi spécifier des colonnes précises si nécessaire, mais ce n’est pas utile ici.
Profitons-en pour mettre cela en cache en même temps.
import { SimpleDB } from "@nshiab/simple-data-analysis";
const sdb = new SimpleDB({ cacheVerbose: true });
const temperatures = sdb.newTable("temperatures");
await temperatures.cache(async () => {
await temperatures.loadData(
"https://raw.githubusercontent.com/nshiab/simple-data-analysis/refs/heads/main/test/data/files/dailyTemperatures.csv",
);
// await temperatures.logTable();
const cities = sdb.newTable("cities");
await cities.loadData(
"https://raw.githubusercontent.com/nshiab/simple-data-analysis/refs/heads/main/test/data/files/cities.csv",
);
// await cities.logTable();
await temperatures.join(cities);
await temperatures.removeMissing();
});
await temperatures.summarize({
values: "time",
categories: "city",
});
await temperatures.logTable();
await sdb.done();Et voilà ! Plus aucune température null.
Comme nous avons modifié le code dans la méthode .cache(), vous remarquerez que le message dans le terminal indique que le code est exécuté à nouveau. Plutôt malin, non ? 😉

Regrouper les années en intervalles
L’une de mes ressources préférées lorsque j’analyse des données climatiques est climatedata.ca. Ils ont une excellente section expliquant pourquoi il est important d’utiliser des moyennes sur 30 ans pour identifier des tendances climatiques.
C’est exactement ce que nous allons faire ici !
Tout d’abord, ajoutons une nouvelle colonne avec l’année extraite de time. La méthode .addColumn() nécessite trois arguments :
- Le nom de la nouvelle colonne. Ici, c’est
year. - Le type de données dans la colonne. Ici, c’est
number. - La définition des données dans la colonne. Il s’agit d’une expression SQL (nous y reviendrons plus tard). Nous voulons extraire l’année de
time.
import { SimpleDB } from "@nshiab/simple-data-analysis";
const sdb = new SimpleDB({ cacheVerbose: true });
const temperatures = sdb.newTable("temperatures");
await temperatures.cache(async () => {
await temperatures.loadData(
"https://raw.githubusercontent.com/nshiab/simple-data-analysis/refs/heads/main/test/data/files/dailyTemperatures.csv",
);
// await temperatures.logTable();
const cities = sdb.newTable("cities");
await cities.loadData(
"https://raw.githubusercontent.com/nshiab/simple-data-analysis/refs/heads/main/test/data/files/cities.csv",
);
// await cities.logTable();
await temperatures.join(cities);
await temperatures.removeMissing();
});
await temperatures.addColumn("year", "number", `YEAR(time)`);
await temperatures.logTable();
await sdb.done();YEAR(time) est une expression SQL. Le Structured Query Language est un langage très répandu lorsqu’on travaille avec des bases de données. En interne, SDA fonctionne avec SQL. Mais ne vous inquiétez pas, vous n’avez pas besoin d’être un expert en SQL pour utiliser SDA. Lorsque nous en aurons besoin, il s’agira d’expressions très simples, comme dans l’exemple ci-dessus, et nous apprendrons les bases au fur et à mesure des leçons et projets.

Maintenant, nous pouvons regrouper les années en intervalles avec la méthode .bins(). Comme vous commencez à le comprendre, SDA propose une méthode pour presque tout ce dont vous avez besoin lors de l’analyse de données. 😎
Cette méthode nécessite trois arguments :
- La colonne contenant les valeurs à regrouper
- L’intervalle des groupes
- Le nom de la nouvelle colonne contenant les groupes
Pour vérifier que tout a été fait correctement, nous pouvons afficher le résultat de await temperature.getUniques("bin"), qui retournera toutes les valeurs uniques dans la nouvelle colonne bin.
import { SimpleDB } from "@nshiab/simple-data-analysis";
const sdb = new SimpleDB({ cacheVerbose: true });
const temperatures = sdb.newTable("temperatures");
await temperatures.cache(async () => {
await temperatures.loadData(
"https://raw.githubusercontent.com/nshiab/simple-data-analysis/refs/heads/main/test/data/files/dailyTemperatures.csv",
);
// await temperatures.logTable();
const cities = sdb.newTable("cities");
await cities.loadData(
"https://raw.githubusercontent.com/nshiab/simple-data-analysis/refs/heads/main/test/data/files/cities.csv",
);
// await cities.logTable();
await temperatures.join(cities);
await temperatures.removeMissing();
});
await temperatures.addColumn("year", "number", `YEAR(time)`);
await temperatures.bins("year", 30, "bin");
await temperatures.logTable();
console.log(await temperatures.getUniques("bin"));
await sdb.done();C’est parfait !

Résumer et filtrer les données
Maintenant que nos températures quotidiennes sont bien regroupées en intervalles, nous pouvons facilement calculer la température moyenne par période de 30 ans pour chaque ville.
Utilisons à nouveau la méthode .summarize(). Mais cette fois, nous allons utiliser plus d’options :
- Les valeurs restent nos températures dans la colonne
t. - Il y a maintenant deux catégories : nous voulons conserver les villes et les intervalles.
- Nous voulons calculer la moyenne et compter le nombre de valeurs pour chaque ville et chaque intervalle.
- Nous arrondissons les valeurs à deux décimales.
De plus, la table contient maintenant 15 lignes, mais .logTable() n’affiche que les 10 premières. Nous allons donc lui demander d’en afficher 15 pour mieux voir le résultat.
import { SimpleDB } from "@nshiab/simple-data-analysis";
const sdb = new SimpleDB({ cacheVerbose: true });
const temperatures = sdb.newTable("temperatures");
await temperatures.cache(async () => {
await temperatures.loadData(
"https://raw.githubusercontent.com/nshiab/simple-data-analysis/refs/heads/main/test/data/files/dailyTemperatures.csv",
);
// await temperatures.logTable();
const cities = sdb.newTable("cities");
await cities.loadData(
"https://raw.githubusercontent.com/nshiab/simple-data-analysis/refs/heads/main/test/data/files/cities.csv",
);
// await cities.logTable();
await temperatures.join(cities);
await temperatures.removeMissing();
});
await temperatures.addColumn("year", "number", `YEAR(time)`);
await temperatures.bins("year", 30, "bin");
await temperatures.summarize({
values: "t",
categories: ["city", "bin"],
summaries: ["mean", "count"],
decimals: 2,
});
await temperatures.logTable({ nbRowsToLog: 15 });
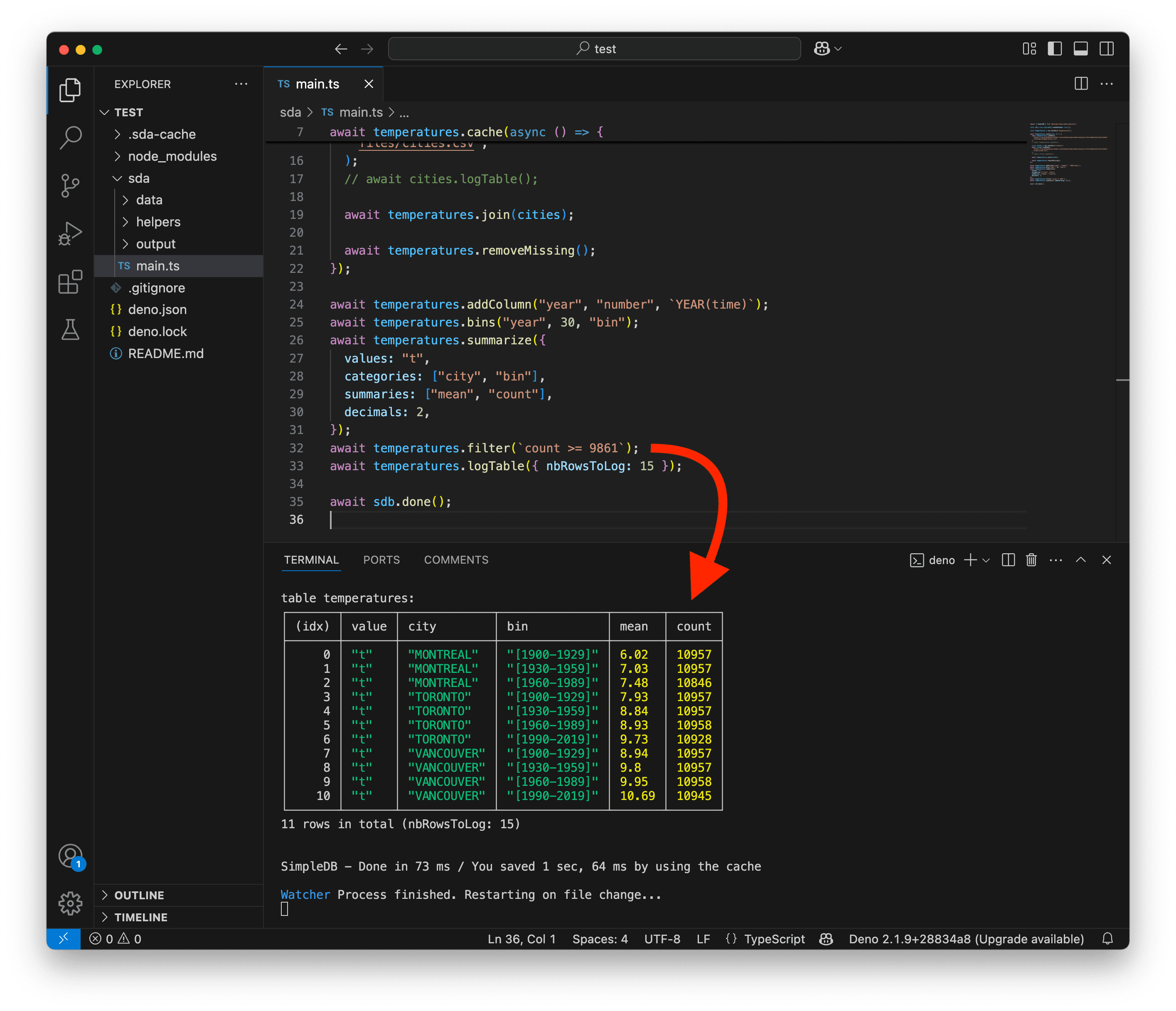
await sdb.done();Voilà qui est intéressant… Grâce à la colonne count, nous pouvons clairement voir où il manque des données.
Bien sûr, les intervalles [2020-2049] sont incomplets, mais l’intervalle [1990-2019] l’est aussi pour MONTREAL. Théoriquement, chaque intervalle de 30 ans devrait contenir environ 10 957 jours.

Nous pourrions exclure les intervalles qui ont moins de 90 % du nombre de jours attendu. Notre seuil serait donc de 9 861 jours.
Pour cela, utilisons la méthode .filter(), qui prend une expression SQL comme condition. Comme vous pouvez le voir ci-dessous, c’est très simple.
import { SimpleDB } from "@nshiab/simple-data-analysis";
const sdb = new SimpleDB({ cacheVerbose: true });
const temperatures = sdb.newTable("temperatures");
await temperatures.cache(async () => {
await temperatures.loadData(
"https://raw.githubusercontent.com/nshiab/simple-data-analysis/refs/heads/main/test/data/files/dailyTemperatures.csv",
);
// await temperatures.logTable();
const cities = sdb.newTable("cities");
await cities.loadData(
"https://raw.githubusercontent.com/nshiab/simple-data-analysis/refs/heads/main/test/data/files/cities.csv",
);
// await cities.logTable();
await temperatures.join(cities);
await temperatures.removeMissing();
});
await temperatures.addColumn("year", "number", `YEAR(time)`);
await temperatures.bins("year", 30, "bin");
await temperatures.summarize({
values: "t",
categories: ["city", "bin"],
summaries: ["mean", "count"],
decimals: 2,
});
await temperatures.filter(`count >= 9861`);
await temperatures.logTable({ nbRowsToLog: 15 });
await sdb.done();Vous n’êtes pas obligé d’utiliser des backticks pour les expressions SQL, comme je l’ai fait aux lignes 24 et 32. Les méthodes attendent simplement du texte. J’ai pris cette habitude parce que les template literals sont pratiques pour injecter des variables dans du texte, et c’est quelque chose que nous ferons souvent avec les expressions SQL, comme nous le verrons dans les prochaines leçons et projets.
Nous avons maintenant 11 lignes restantes.
Tendances
Reformater les données
Que nous souhaitions visualiser les données ou calculer des indicateurs statistiques pour analyser les tendances, nous avons un problème : nos intervalles sont du texte. Il serait bien plus simple de les avoir sous forme de nombres.
Le code ci-dessous résout ce problème :
- À la ligne 33, nous utilisons la méthode
.splitExtract()pour diviser les intervalles sur le caractère-, puis nous prenons la première partie (index0) et l’ajoutons dans une nouvelle colonnestartYear. - À la ligne 34, nous supprimons le
[restant. - Enfin, à la ligne 35, nous convertissons les valeurs de la colonne
startYearennumber.
Petit astuce: vous pouvez toujours survoler les méthodes avec votre curseur pour voir leur documentation et des exemples. J’ai pris le temps de documenter chacune d’elles. 🫡
import { SimpleDB } from "@nshiab/simple-data-analysis";
const sdb = new SimpleDB({ cacheVerbose: true });
const temperatures = sdb.newTable("temperatures");
await temperatures.cache(async () => {
await temperatures.loadData(
"https://raw.githubusercontent.com/nshiab/simple-data-analysis/refs/heads/main/test/data/files/dailyTemperatures.csv",
);
// await temperatures.logTable();
const cities = sdb.newTable("cities");
await cities.loadData(
"https://raw.githubusercontent.com/nshiab/simple-data-analysis/refs/heads/main/test/data/files/cities.csv",
);
// await cities.logTable();
await temperatures.join(cities);
await temperatures.removeMissing();
});
await temperatures.addColumn("year", "number", `YEAR(time)`);
await temperatures.bins("year", 30, "bin");
await temperatures.summarize({
values: "t",
categories: ["city", "bin"],
summaries: ["mean", "count"],
decimals: 2,
});
await temperatures.filter(`count >= 9861`);
await temperatures.splitExtract("bin", "-", 0, "startYear");
await temperatures.trim("startYear", { character: "[" });
await temperatures.convert({ startYear: "number" });
await temperatures.logTable({ nbRowsToLog: 15 });
await sdb.done();
Visualisation dans le terminal
Nous pouvons maintenant facilement visualiser nos données !
Avec SDA, vous pouvez créer des graphiques de base directement dans votre terminal. Ici, nous utilisons .logDotChart(), et nous pouvons clairement voir comment les températures ont augmenté au cours du siècle dernier.
import { SimpleDB } from "@nshiab/simple-data-analysis";
const sdb = new SimpleDB({ cacheVerbose: true });
const temperatures = sdb.newTable("temperatures");
await temperatures.cache(async () => {
await temperatures.loadData(
"https://raw.githubusercontent.com/nshiab/simple-data-analysis/refs/heads/main/test/data/files/dailyTemperatures.csv",
);
// await temperatures.logTable();
const cities = sdb.newTable("cities");
await cities.loadData(
"https://raw.githubusercontent.com/nshiab/simple-data-analysis/refs/heads/main/test/data/files/cities.csv",
);
// await cities.logTable();
await temperatures.join(cities);
await temperatures.removeMissing();
});
await temperatures.addColumn("year", "number", `YEAR(time)`);
await temperatures.bins("year", 30, "bin");
await temperatures.summarize({
values: "t",
categories: ["city", "bin"],
summaries: ["mean", "count"],
decimals: 2,
});
await temperatures.filter(`count >= 9861`);
await temperatures.splitExtract("bin", "-", 0, "startYear");
await temperatures.trim("startYear", { character: "[" });
await temperatures.convert({ startYear: "number" });
await temperatures.logTable({ nbRowsToLog: 15 });
await temperatures.logDotChart("startYear", "mean", { smallMultiples: "city" });
await sdb.done();
Visualisation avec Plot
Les visualisations dans le terminal sont assez limitées. Si vous voulez créer des graphiques plus élaborés, vous pouvez utiliser Observable Plot, qui a été installé lors de la configuration avec setup-sda.
Nous ferons une leçon complète sur Plot plus tard. Cela peut sembler compliqué pour l’instant, mais une fois que vous aurez assimilé les bases, vous verrez que c’est une librairie de visualisation de données exceptionnelle.
Dans l’exemple ci-dessous, nous écrivons un graphique sous forme de fichier PNG dans notre dossier ./sda/output.
import { SimpleDB } from "@nshiab/simple-data-analysis";
import { dot, line, plot } from "@observablehq/plot";
const sdb = new SimpleDB({ cacheVerbose: true });
const temperatures = sdb.newTable("temperatures");
await temperatures.cache(async () => {
await temperatures.loadData(
"https://raw.githubusercontent.com/nshiab/simple-data-analysis/refs/heads/main/test/data/files/dailyTemperatures.csv",
);
// await temperatures.logTable();
const cities = sdb.newTable("cities");
await cities.loadData(
"https://raw.githubusercontent.com/nshiab/simple-data-analysis/refs/heads/main/test/data/files/cities.csv",
);
// await cities.logTable();
await temperatures.join(cities);
await temperatures.removeMissing();
});
await temperatures.addColumn("year", "number", `YEAR(time)`);
await temperatures.bins("year", 30, "bin");
await temperatures.summarize({
values: "t",
categories: ["city", "bin"],
summaries: ["mean", "count"],
decimals: 2,
});
await temperatures.filter(`count >= 9861`);
await temperatures.splitExtract("bin", "-", 0, "startYear");
await temperatures.trim("startYear", { character: "[" });
await temperatures.convert({ startYear: "number" });
await temperatures.logTable({ nbRowsToLog: 15 });
const chart = (data: unknown[]) =>
plot({
inset: 20,
marginLeft: 50,
marginBottom: 40,
grid: true,
y: { tickFormat: (d) => `${d}°C`, label: "Temperature", ticks: 5 },
x: {
tickFormat: (d) => `${d}-${d + 29}`,
ticks: [1900, 1930, 1960, 1990],
label: "Year",
},
color: { legend: true },
marks: [
line(data, {
x: "startYear",
y: "mean",
stroke: "city",
curve: "natural",
}),
dot(data, {
x: "startYear",
y: "mean",
fill: "white",
stroke: "city",
strokeWidth: 2,
r: 4,
}),
],
});
await temperatures.writeChart(
chart,
"./sda/output/temperatures.png",
);
await sdb.done();
Vous pouvez ouvrir toutes sortes de fichiers avec VS Code, y compris les images. Comme nous surveillons main.ts, chaque fois que nous mettons à jour le code générant le graphique, temperatures.png est réécrit et mis à jour dans son onglet. Autre astuce : vous pouvez déplacer l’onglet temperatures.png où vous le souhaitez, y compris sur un deuxième écran si vous en avez un.
Corrélations et régressions linéaires
Les visualisations sont utiles, mais leur interprétation peut être subjective.
Pour analyser les tendances, vous pouvez aussi vous appuyer sur des indicateurs statistiques comme les corrélations et les régressions linéaires. Si vous souhaitez en savoir plus sur ces concepts, consultez la leçon Maths pour les journalistes.
Commençons par les corrélations. Notez que j’ai supprimé le code générant le graphique.
Comme .summarize(), la méthode .correlations() remplace les données de la table par les résultats de ses calculs.
import { SimpleDB } from "@nshiab/simple-data-analysis";
const sdb = new SimpleDB({ cacheVerbose: true });
const temperatures = sdb.newTable("temperatures");
await temperatures.cache(async () => {
await temperatures.loadData(
"https://raw.githubusercontent.com/nshiab/simple-data-analysis/refs/heads/main/test/data/files/dailyTemperatures.csv",
);
// await temperatures.logTable();
const cities = sdb.newTable("cities");
await cities.loadData(
"https://raw.githubusercontent.com/nshiab/simple-data-analysis/refs/heads/main/test/data/files/cities.csv",
);
// await cities.logTable();
await temperatures.join(cities);
await temperatures.removeMissing();
});
await temperatures.addColumn("year", "number", `YEAR(time)`);
await temperatures.bins("year", 30, "bin");
await temperatures.summarize({
values: "t",
categories: ["city", "bin"],
summaries: ["mean", "count"],
decimals: 2,
});
await temperatures.filter(`count >= 9861`);
await temperatures.splitExtract("bin", "-", 0, "startYear");
await temperatures.trim("startYear", { character: "[" });
await temperatures.convert({ startYear: "number" });
await temperatures.correlations({
x: "startYear",
y: "mean",
categories: "city",
});
await temperatures.logTable({ nbRowsToLog: 15 });
await sdb.done();Comme nous pouvons le voir, les corrélations sont proches de 1, ce qui signifie qu’il existe une forte relation entre les années et la température. Quand l’une augmente, l’autre aussi.

Nous pouvons également calculer des régressions linéaires, qui sont plus descriptives. Il suffit de remplacer la méthode .correlations par .linearRegressions à la ligne 37 et d’ajouter l’option decimals: 2 pour arrondir les valeurs à la ligne 41.
Encore une fois, le r2 est proche de 1, ce qui signifie que les deux variables sont liées. La slope nous indique aussi que la température a augmenté de 0,02°C par an en moyenne.
Ces trois villes canadiennes se sont réchauffées ! 🌡️🌡️🌡️

Écriture des données
Pour finir en beauté, écrivons nos résultats dans un fichier. Avec la méthode .writeData(), vous pouvez enregistrer des fichiers au format CSV, JSON et Parquet. Si vous travaillez avec de gros fichiers, des options sont disponibles pour les compresser.
import { SimpleDB } from "@nshiab/simple-data-analysis";
const sdb = new SimpleDB({ cacheVerbose: true });
const temperatures = sdb.newTable("temperatures");
await temperatures.cache(async () => {
await temperatures.loadData(
"https://raw.githubusercontent.com/nshiab/simple-data-analysis/refs/heads/main/test/data/files/dailyTemperatures.csv",
);
// await temperatures.logTable();
const cities = sdb.newTable("cities");
await cities.loadData(
"https://raw.githubusercontent.com/nshiab/simple-data-analysis/refs/heads/main/test/data/files/cities.csv",
);
// await cities.logTable();
await temperatures.join(cities);
await temperatures.removeMissing();
});
await temperatures.addColumn("year", "number", `YEAR(time)`);
await temperatures.bins("year", 30, "bin");
await temperatures.summarize({
values: "t",
categories: ["city", "bin"],
summaries: ["mean", "count"],
decimals: 2,
});
await temperatures.filter(`count >= 9861`);
await temperatures.splitExtract("bin", "-", 0, "startYear");
await temperatures.trim("startYear", { character: "[" });
await temperatures.convert({ startYear: "number" });
await temperatures.linearRegressions({
x: "startYear",
y: "mean",
categories: "city",
decimals: 2,
});
await temperatures.logTable({ nbRowsToLog: 15 });
await temperatures.writeData("./sda/output/temperatures.csv");
await sdb.done();Conclusion
Eh bien, quelle aventure ! 🎉 C’était votre premier projet avec SDA !
J’espère que vous voyez l’intérêt de cette librairie. Avec ses méthodes simples à utiliser, vous pouvez réaliser des analyses complexes.
Jusqu’à présent, nous avons travaillé avec deux petits fichiers, mais la librairie est aussi extrêmement performante. Attendez de traiter votre premier fichier d’un milliard de lignes. 😇 (Oui, ce n’est pas une blague—nous allons vraiment le faire dans un futur projet.)
Mais avant cela, passons à la prochaine leçon sur les données géospatiales. C’est une autre force de SDA : vous pouvez aussi l’utiliser avec des géométries, des coordonnées et des cartes ! 🌎