Exploiter les données du recensement 🇨🇦
Bienvenue dans ce nouveau projet ! Nous allons explorer l’immense quantité d’informations provenant du recensement canadien fourni par Statistique Canada ! Pour traiter les données, nous utiliserons la librairie Simple Data Analysis (SDA), que j’ai créée (donnez-lui une étoile ⭐).
Pour chaque région métropolitaine, nous créerons une carte montrant les zones où les revenus des ménages sont inférieurs ou supérieurs à la médiane. La carte de Montréal ci-dessous est un exemple du résultat final que nous allons obtenir ensemble.

Dans ce projet, je vais vous montrer des techniques avancées pour traiter de grands ensembles de données avec TypeScript. Les données du recensement de 2021 pèsent environ 30 GB, mais vous aurez besoin d’environ 70 GB d’espace libre sur votre disque dur pour ce projet. Il est temps de faire un peu de ménage ! 🧹
Si vous êtes bloqué à un moment donné, il peut être utile de revoir les leçons précédentes expliquant les bases de SDA :
Nous utiliserons Deno et VS Code. Consultez la leçon Installation si nécessaire.
C’est parti !
Quelle est la question ?
Pour ne pas perdre le fil, définissons la question à laquelle nous essayons de répondre :
- Pour chaque région métropolitaine canadienne, quelles sont les aires de diffusion dont le revenu des ménages est supérieur ou inférieur à la médiane ?
Les régions métropolitaines sont définies ainsi dans le recensement :
Une région métropolitaine de recensement (RMR) est formée d’une ou de plusieurs municipalités adjacentes centrées sur une région urbaine (appelée le noyau). Une RMR doit avoir une population totale d’au moins 100 000 habitants, dont au moins 50 000 vivent dans le noyau.
Voici la définition des aires de diffusion :
Une aire de diffusion (AD) est une petite unité géographique relativement stable avec une population moyenne de 400 à 700 personnes. C’est la plus petite unité géographique pour laquelle toutes les données de recensement sont diffusées. Les AD couvrent tout le territoire canadien.
C’est parti pour le code !
Configuration
Pour tout configurer, utilisons setup-sda comme dans les leçons précédentes.
Créez un nouveau dossier, ouvrez-le avec VS Code, et exécutez : deno -A jsr:@nshiab/setup-sda
Ensuite, exécutez deno task sda pour surveiller main.ts et ses dépendances.

Pour que SDA fonctionne correctement, il est recommandé d’avoir au moins la version 2.1.9 de Deno. Pour vérifier votre version, exécutez deno --version dans votre terminal. Pour la mettre à jour, exécutez simplement deno upgrade.
Téléchargement des données
Pour télécharger les données du recensement avec le plus de granularité possible, cliquez sur cette page de Statistique Canada.
Cliquez sur le premier volet Fichier de téléchargement complet puis sur le bouton CSV pour Canada, provinces, territoires, divisions de recensement (DR), subdivisions de recensement (SDR) et aires de diffusion (AD).
Si vous ne le trouvez pas, voici le lien direct. Cela téléchargera un fichier zip de 2,25 GB.

Parce que nous voulons travailler sur les régions métropolitaines, il serait utile d’avoir les noms des régions pour chaque aire de diffusion.
Le fichier contenant ces informations se trouve ici. Téléchargez-le aussi. C’est un autre fichier zip de 9,8 MB.

Et enfin, comme nous voulons créer une carte, nous avons besoin des frontières géospatiales des aires de diffusion. Vous les trouverez ici.
Déplacez tout cela dans le dossier data de votre projet et décompressez tout sauf les frontières géospatiales dans le fichier lda_000b21a_e.zip ! C’est décompressé dans mes captures d’écran, mais c’était une erreur 🥲.
Surprise ! Vous avez maintenant plus de 27 GB de données à traiter. 😅

Les données du recensement
Premier essai
En décompressant les données, nous avons obtenu un dossier contenant plusieurs fichiers. Les données se trouvent dans les fichiers dont le nom contient _data_.
Essayons d’ouvrir le premier pour les provinces de l’Atlantique.
import { SimpleDB } from "@nshiab/simple-data-analysis";
const sdb = new SimpleDB();
const census = sdb.newTable("census");
await census.loadData(
"sda/data/98-401-X2021006_eng_CSV/98-401-X2021006_English_CSV_data_Atlantic.csv",
);
await census.logTable()
await sdb.done();Hmmm… Nous avons un problème. Cette erreur signifie que les données n’utilisent pas l’encodage UTF-8, qui est pourtant la norme de nos jours et nécessaire pour SDA.

J’ai contacté Statistique Canada à ce sujet, et ils m’ont dit qu’ils utilisaient l’encodage Windows-1252. Cela signifie que notre première étape consiste à réencoder les données…
Et oui, les projets de données dans la vraie vie sont toujours aussi amusants ! 😬
Réencodage des données
Comme le réencodage de données est une tâche courante, j’ai créé la fonction reencode et je l’ai publiée dans la librairie journalism. Lorsque vous configurez votre projet avec setup-sda, journalism est automatiquement installé. Cette étape sera donc très facile !
Créons un nouveau fichier toUTF8.ts dans le dossier helpers avec le code ci-dessous. Comme nous n’avons besoin de réencoder les données qu’une seule fois, nous n’exportons pas de fonction. C’est simplement un script que nous allons exécuter une seule fois.
En regardant les noms des fichiers, vous remarquerez qu’ils ont tous la même structure, sauf pour la région. En créant une liste avec les régions, nous pouvons facilement parcourir tous les fichiers.
La fonction reencode nécessite quatre arguments :
- le fichier d’entrée
- le fichier de sortie, qui ici a le même nom que le fichier original mais avec
_utf8à la fin - l’encodage d’origine
- le nouvel encodage
import { reencode } from "@nshiab/journalism";
const regions = [
"Atlantic",
"BritishColumbia",
"Ontario",
"Prairies",
"Quebec",
"Territories",
];
for (const r of regions) {
console.log(`Processing ${r}`);
const newFile =
`sda/data/98-401-X2021006_eng_CSV/98-401-X2021006_English_CSV_data_${r}_utf8.csv`;
const originalFile =
`sda/data/98-401-X2021006_eng_CSV/98-401-X2021006_English_CSV_data_${r}.csv`;
await reencode(originalFile, newFile, "windows-1252", "utf-8");
console.log(`Done with ${r}`);
}Pour exécuter ce script, nous pouvons créer une nouvelle tâche toUTF8 dans notre deno.json. Ne vous inquiétez pas si vous n’avez pas la même version que moi dans les imports. Tout va bien aller !
{
"tasks": {
"sda": "deno run --node-modules-dir=auto -A --watch --check sda/main.ts",
"clean": "rm -rf .sda-cache && rm -rf .tmp",
"toUTF8": "deno run -A sda/helpers/toUTF8.ts"
},
"nodeModulesDir": "auto",
"imports": {
"@nshiab/journalism": "jsr:@nshiab/journalism@^1.22.0",
"@nshiab/simple-data-analysis": "jsr:@nshiab/simple-data-analysis@^4.2.0",
"@observablehq/plot": "npm:@observablehq/plot@^0.6.17"
}
}Arrêtez de surveiller main.ts (CTRL + C dans votre terminal) et exécutons notre nouveau script avec notre nouvelle tâche : deno task toUTF8
Cela prendra quelques minutes pour réencoder tous les fichiers. Voici ce que vous verrez une fois que ce sera terminé.

De nouveaux fichiers sont apparus avec _utf8 dans leurs noms ! Et maintenant, votre dossier data pèse… 53 GB. 🤭
Si vous manquez d’espace de stockage, supprimez les fichiers de données d’origine. Nous travaillerons désormais avec ceux qui se terminent par _utf8.csv. Gardez également les autres fichiers, en particulier 98-401-X2021006_English_meta.txt !
Réessayons
Essayons maintenant de charger et d’afficher le fichier CSV réencodé pour les provinces de l’Atlantique. Mettez à jour main.ts et exécutez deno task sda dans votre terminal.
import { SimpleDB } from "@nshiab/simple-data-analysis";
const sdb = new SimpleDB();
const census = sdb.newTable("census");
await census.loadData(
"sda/data/98-401-X2021006_eng_CSV/98-401-X2021006_English_CSV_data_Atlantic_utf8.csv",
);
await census.logTable();
await sdb.done();
Si la disposition du tableau s’affiche de manière étrange dans votre terminal, c’est parce que la largeur du tableau est supérieure à celle de votre terminal. Faites un clic droit sur le terminal et cherchez Toggle size with content width. Il y a aussi un raccourci pratique que j’utilise tout le temps pour cela : OPTION + Z sur Mac et ALT + Z sur PC.
Ça fonctionne ! 🥳
Essayons un autre fichier : celui des Prairies, qui couvre les provinces de l’Alberta, de la Saskatchewan et du Manitoba.
import { SimpleDB } from "@nshiab/simple-data-analysis";
const sdb = new SimpleDB();
const census = sdb.newTable("census");
await census.loadData(
"sda/data/98-401-X2021006_eng_CSV/98-401-X2021006_English_CSV_data_Prairies_utf8.csv",
);
await census.logTable();
await sdb.done();
Oh non ! Encore une erreur… Il semble que ce fichier CSV soit mal formaté…
Nous pouvons ajuster les options pour rendre le chargement du CSV moins stricte et voir si cela fonctionne.
import { SimpleDB } from "@nshiab/simple-data-analysis";
const sdb = new SimpleDB();
const census = sdb.newTable("census");
await census.loadData(
"sda/data/98-401-X2021006_eng_CSV/98-401-X2021006_English_CSV_data_Prairies_utf8.csv",
{ strict: false },
);
await census.logTable();
await sdb.done();
Magnifique ! Tout fonctionne maintenant !
Charger toutes les données
Jusqu’à présent, nous avons chargé les données un fichier à la fois. Mais vous pouvez également charger tous les fichiers CSV dans une seule table facilement.
Créons un nouveau fichier crunchData.ts pour cela. Cette fonction async aura un paramètre sdb et retournera une table census.
Lorsque vous avez des fichiers dont les noms suivent le même modèle, vous pouvez utiliser des jokers *. Dans notre cas, nous voulons charger tous les fichiers CSV se terminant par _utf8.csv, donc nous les chargeons tous en utilisant *_utf8.csv, comme montré à la ligne 6 ci-dessous.
import { SimpleDB } from "@nshiab/simple-data-analysis";
export default async function crunchData(sdb: SimpleDB) {
const census = sdb.newTable("census");
await census.loadData("sda/data/98-401-X2021006_eng_CSV/*_utf8.csv",
{
strict: false,
});
return census;
}Mettons à jour main.ts pour utiliser cette nouvelle fonction. Nous réglons également cacheVerbose sur true lors de la création de notre SimpleDB. Cela enregistrera la durée totale et sera utile par la suite lorsque nous utiliserons le cache.
import { SimpleDB } from "@nshiab/simple-data-analysis";
import crunchData from "./helpers/crunchData.ts";
const sdb = new SimpleDB({ cacheVerbose: true });
const census = await crunchData(sdb);
await census.logTable();
await sdb.done();En fonction de la mémoire RAM disponible sur votre ordinateur, vous pourriez voir un dossier .tmp apparaître. Si les données sont plus volumineuses que votre RAM, ce dossier sera utilisé pour traiter toutes les données en y stockant des morceaux prétraités.
Ce dossier .tmp peut devenir assez volumineux. Sur ma machine, après la première exécution, il pèse environ 16 GB.
Si vous souhaitez nettoyer votre cache, exécutez deno task clean. Cela supprimera .tmp et .sda-cache (nous en reparlerons plus tard). Vous pouvez également les supprimer manuellement, mais n’oubliez pas de vider votre corbeille.
Nous pouvons enfin jeter un œil aux données. Avec 166 millions de lignes et 23 colonnes, nous avons environ 3,8 milliards de points de données. 🙃
Et charger tout cela a pris moins d’une minute sur mon ordinateur. Pas mal !

Limite et cache
Pour commencer à travailler sur les données, nous n’avons pas besoin de tout charger. Nous pouvons utiliser l’option limit pour ne charger que le premier million de lignes.
Maintenant, le chargement des données prend environ une seconde.
import { SimpleDB } from "@nshiab/simple-data-analysis";
export default async function crunchData(sdb: SimpleDB) {
const census = sdb.newTable("census");
await census.loadData("sda/data/98-401-X2021006_eng_CSV/*_utf8.csv", {
strict: false,
limit: 1_000_000,
});
return census;
}
Nous pouvons également utiliser la méthode cache. Tout ce qui est enveloppé par cette méthode sera exécuté une seule fois et le résultat sera stocké dans le dossier .sda-cache. Si le code ne change pas dans la méthode cache, les données seront chargées depuis le cache au lieu de relancer les calculs.
Lors de la première exécution, cela prend un peu plus de temps car les données sont écrites dans le cache.
import { SimpleDB } from "@nshiab/simple-data-analysis";
export default async function crunchData(sdb: SimpleDB) {
const census = sdb.newTable("census");
await census.cache(async () => {
await census.loadData("sda/data/98-401-X2021006_eng_CSV/*_utf8.csv", {
strict: false,
limit: 1_000_000,
});
});
return census;
}
Mais lors des exécutions suivantes, les données sont chargées depuis le cache, ce qui est beaucoup plus rapide. Sur mon MacBook Pro, c’est 10 fois plus rapide ! 😱

Filtrage
L’une des premières choses à faire lorsque l’on travaille avec de grands ensembles de données est de les filtrer pour ne conserver que les informations qui nous intéressent.
Notre question est :
- Pour chaque région métropolitaine canadienne, quelles sont les aires de diffusion dont le revenu des ménages est supérieur ou inférieur à la médiane ?
Pour trouver le revenu total des ménages, vous pouvez consulter le fichier 98-401-X2021006_English_meta.txt. Il contient la liste de toutes les variables du recensement.
Le CHARACTERISTIC_ID pour le Median total income of household in 2020 ($) est 243.

De plus, les fichiers de données du recensement que nous avons téléchargés contiennent différents niveaux géographiques, mais nous avons seulement besoin des aires de diffusion.
Enfin, nous n’avons besoin que de trois colonnes :
DGUID, qui contient l’ID géospatial unique des aires de diffusion. Nous l’utiliserons pour trouver les bonnes frontières pour créer une carte.GEO_NAME, qui contient l’ID de nommage unique des aires de diffusion. Nous l’utiliserons pour récupérer les noms des régions métropolitaines.C1_COUNT_TOTAL, qui contient les valeurs de la variable. Dans notre cas, il s’agit du revenu total médian dans chaque aire de diffusion. Nous pouvons renommer cette colonne pour avoir quelque chose de plus lisible.
Mettons à jour crunchData pour ne conserver que ce dont nous avons besoin.
import { SimpleDB } from "@nshiab/simple-data-analysis";
export default async function crunchData(sdb: SimpleDB) {
const census = sdb.newTable("census");
await census.cache(async () => {
await census.loadData("sda/data/98-401-X2021006_eng_CSV/*_utf8.csv", {
strict: false,
limit: 1_000_000,
});
await census.keep({
GEO_LEVEL: "Dissemination area",
CHARACTERISTIC_ID: [243], // Median total income of household in 2020 ($)
});
await census.selectColumns([
"DGUID",
"GEO_NAME",
"C1_COUNT_TOTAL",
]);
await census.renameColumns({ C1_COUNT_TOTAL: "medianIncome" });
});
return census;
}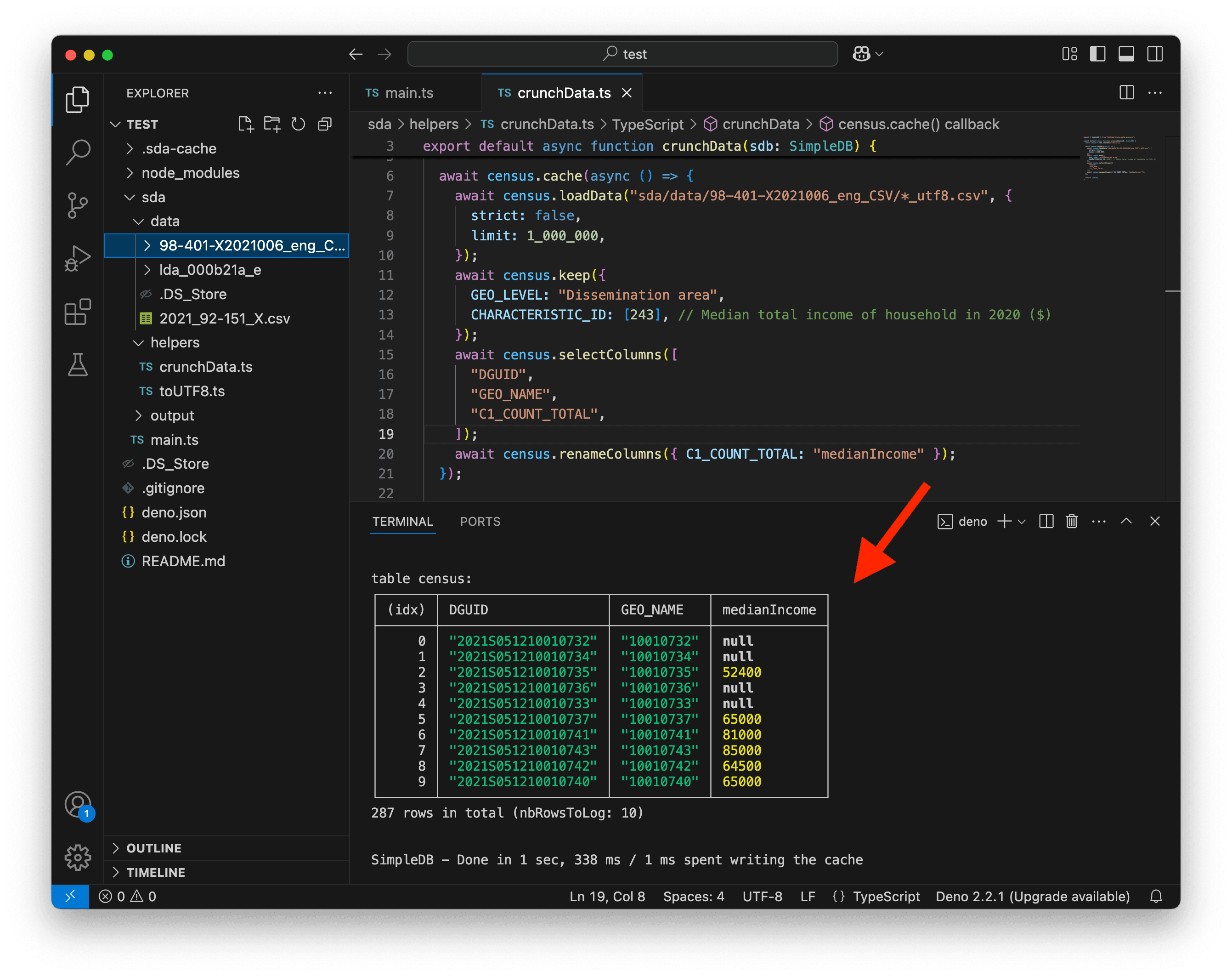
C’est beaucoup mieux ! Nous pouvons maintenant nous concentrer sur l’ajout des noms des régions métropolitaines.
Les régions métropolitaines
Premier essai
Essayons de charger les noms qui se trouvent dans le fichier 2021_92-151_X.csv. Nous pouvons mettre à jour crunchData.ts. Nous continuons de travailler dans la méthode cache.
import { SimpleDB } from "@nshiab/simple-data-analysis";
export default async function crunchData(sdb: SimpleDB) {
const census = sdb.newTable("census");
await census.cache(async () => {
await census.loadData("sda/data/98-401-X2021006_eng_CSV/*_utf8.csv", {
strict: false,
limit: 1_000_000,
});
await census.keep({
GEO_LEVEL: "Dissemination area",
CHARACTERISTIC_ID: [243], // Median total income of household in 2020 ($)
});
await census.selectColumns([
"DGUID",
"GEO_NAME",
"C1_COUNT_TOTAL",
]);
await census.renameColumns({ C1_COUNT_TOTAL: "medianIncome" });
const names = sdb.newTable("names");
await names.loadData("sda/data/2021_92-151_X.csv");
await names.logTable();
});
return census;
}
Nous connaissons cette erreur ! C’est encore un problème d’encodage !
Réencodage à nouveau
Mettons à jour toUTF8.ts pour convertir également ce fichier CSV. Nous commentons le code précédent car nous n’avons pas besoin de reconvertir les fichiers du recensement.
import { reencode } from "@nshiab/journalism";
// const regions = [
// "Atlantic",
// "BritishColumbia",
// "Ontario",
// "Prairies",
// "Quebec",
// "Territories",
// ];
// for (const r of regions) {
// console.log(`Processing ${r}`);
// const newFile =
// `sda/data/98-401-X2021006_eng_CSV/98-401-X2021006_English_CSV_data_${r}_utf8.csv`;
// const originalFile =
// `sda/data/98-401-X2021006_eng_CSV/98-401-X2021006_English_CSV_data_${r}.csv`;
// await reencode(originalFile, newFile, "windows-1252", "utf-8");
// console.log(`Done with ${r}`);
// }
console.log(`Processing names data`);
await reencode(
"sda/data/2021_92-151_X.csv",
"sda/data/2021_92-151_X_utf8.csv",
"windows-1252",
"utf-8",
);
console.log("Done with names data");Arrêtez de surveiller main.ts dans votre terminal (CTRL + C) et exécutez deno task toUTF8.
Maintenant, chargeons notre nouveau fichier sda/data/2021_92-151_X_utf8.csv dans crunchData.ts.
import { SimpleDB } from "@nshiab/simple-data-analysis";
export default async function crunchData(sdb: SimpleDB) {
const census = sdb.newTable("census");
await census.cache(async () => {
await census.loadData("sda/data/98-401-X2021006_eng_CSV/*_utf8.csv", {
strict: false,
limit: 1_000_000,
});
await census.keep({
GEO_LEVEL: "Dissemination area",
CHARACTERISTIC_ID: [243], // Median total income of household in 2020 ($)
});
await census.selectColumns([
"DGUID",
"GEO_NAME",
"C1_COUNT_TOTAL",
]);
await census.renameColumns({ C1_COUNT_TOTAL: "medianIncome" });
const names = sdb.newTable("names");
await names.loadData("sda/data/2021_92-151_X_utf8.csv");
await names.logTable();
});
return census;
}
Encore une erreur… Nous devons à nouveau définir l’option strict sur false.
import { SimpleDB } from "@nshiab/simple-data-analysis";
export default async function crunchData(sdb: SimpleDB) {
const census = sdb.newTable("census");
await census.cache(async () => {
await census.loadData("sda/data/98-401-X2021006_eng_CSV/*_utf8.csv", {
strict: false,
limit: 1_000_000,
});
await census.keep({
GEO_LEVEL: "Dissemination area",
CHARACTERISTIC_ID: [243], // Median total income of household in 2020 ($)
});
await census.selectColumns([
"DGUID",
"GEO_NAME",
"C1_COUNT_TOTAL",
]);
await census.renameColumns({ C1_COUNT_TOTAL: "medianIncome" });
const names = sdb.newTable("names");
await names.loadData("sda/data/2021_92-151_X_utf8.csv", { strict: false });
await names.logTable();
});
return census;
}Et maintenant, ça fonctionne ! Mais ce fichier contient un impressionnant total de 63 colonnes. 😳
Filtrage
Si vous lisez la documentation (et que vous connaissez bien votre recensement 🥸), vous réaliserez que vous n’avez besoin que de deux colonnes, après avoir filtré CMATYPE_RMRGENRE pour le type B afin de ne conserver que les régions métropolitaines.
Comme le fichier contient des données pour différents niveaux géographiques, nous supprimons les doublons créés en sélectionnant seulement deux colonnes. Et puisque le but est d’ajouter les noms des régions métropolitaines à notre table census, nous renommons la colonne DADGUID_ADIDUGD en DGUID pour joindre facilement les deux tables. Nous renommons également CMANAME_RMRNOM en CMA par souci de commodité.
Voici une version mise à jour de crunchData.ts.
import { SimpleDB } from "@nshiab/simple-data-analysis";
export default async function crunchData(sdb: SimpleDB) {
const census = sdb.newTable("census");
await census.cache(async () => {
await census.loadData("sda/data/98-401-X2021006_eng_CSV/*_utf8.csv", {
strict: false,
limit: 1_000_000,
});
await census.keep({
GEO_LEVEL: "Dissemination area",
CHARACTERISTIC_ID: [243], // Median total income of household in 2020 ($)
});
await census.selectColumns([
"DGUID",
"GEO_NAME",
"C1_COUNT_TOTAL",
]);
await census.renameColumns({ C1_COUNT_TOTAL: "medianIncome" });
const names = sdb.newTable("names");
await names.loadData("sda/data/2021_92-151_X_utf8.csv", { strict: false });
await names.keep({
CMATYPE_RMRGENRE: "B",
});
await names.selectColumns(["DADGUID_ADIDUGD", "CMANAME_RMRNOM"]);
await names.removeDuplicates();
await names.renameColumns({
DADGUID_ADIDUGD: "DGUID",
CMANAME_RMRNOM: "CMA",
});
await census.join(names);
});
return census;
}
Victoire ! Nous avons maintenant le nom de la région métropolitaine pour chaque aire de diffusion ! 🥳
Les frontières des aires de diffusion
Simplification
Comme nous voulons créer une carte, nous avons besoin des frontières des aires de diffusion. Nous les avons téléchargées précédemment sous forme de fichier compressé lda_000b21a_e.zip (et je vous avais dit de ne pas le décompresser 😬).
Statistique Canada fournit des données géospatiales très détaillées. Mais comme nous voulons seulement dessiner des cartes, nous n’avons pas besoin d’un niveau de détail aussi élevé. Une version simplifiée suffira et rendra notre code plus rapide.
Un de mes outils préférés pour simplifier les données géospatiales est mapshaper.org. Allez leur donner une ⭐ sur GitHub si vous avez un compte !
Allez sur le site et faites glisser lda_000b21a_e.zip sur la page. Notez que vous ne pouvez pas faire glisser le fichier depuis VS Code. Faites-le depuis votre dossier à l’aide du Finder ou de l’Explorateur de fichiers de votre ordinateur.
Après quelques secondes, vous verrez toutes les aires de diffusion.

Vous pouvez maintenant cliquer sur Simplify en haut à droite et sélectionner les options suivantes :
prevent shape removalVisvalingam / weighted area
Cliquez sur Apply !

Pour l’étape suivante, je zoome généralement sur une zone à haute densité, comme Montréal. Ensuite, à l’aide du curseur en haut, je vise un seuil de simplification qui ne modifie pas les formes globales.
Ici, 10% fonctionne plutôt bien. Notez que vous pouvez également saisir directement le pourcentage souhaité.

L’étape suivante consiste à exporter les données simplifiées !
Cliquez sur le bouton Export en haut à droite, conservez le format de fichier original Shapefile, puis cliquez sur Export.

Vous pouvez maintenant renommer ce fichier en lda_000b21a_e_simplified.shp.zip (remarquez que j’ai ajouté .shp.zip à l’extension pour aider SDA à comprendre qu’il s’agit d’un shapefile) et le déplacer dans votre dossier data.
Au lieu de 197 MB, nos données géospatiales ne pèsent plus que 27 MB, ce qui accélérera nos calculs et le dessin des cartes !
Chargement des géométries
Pour charger les géométries, nous pouvons utiliser la méthode loadGeoData. N’oubliez pas de modifier l’extension du fichier Shapefile simplifié en .shp.zip. Le shp est important pour SDA. Sans cela, SDA ne reconnaît pas le fichier en tant que Shapefile et ne peut pas le charger correctement.
Lorsque vous chargez de nouvelles données géospatiales, il est toujours important de vérifier la projection. Ci-dessous, nous utilisons la méthode logProjections pour cela.
import { SimpleDB } from "@nshiab/simple-data-analysis";
export default async function crunchData(sdb: SimpleDB) {
const census = sdb.newTable("census");
await census.cache(async () => {
await census.loadData("sda/data/98-401-X2021006_eng_CSV/*_utf8.csv", {
strict: false,
limit: 1_000_000,
});
await census.keep({
GEO_LEVEL: "Dissemination area",
CHARACTERISTIC_ID: [243], // Median total income of household in 2020 ($)
});
await census.selectColumns([
"DGUID",
"GEO_NAME",
"C1_COUNT_TOTAL",
]);
await census.renameColumns({ C1_COUNT_TOTAL: "medianIncome" });
const names = sdb.newTable("names");
await names.loadData("sda/data/2021_92-151_X_utf8.csv", { strict: false });
await names.keep({
CMATYPE_RMRGENRE: "B",
});
await names.selectColumns(["DADGUID_ADIDUGD", "CMANAME_RMRNOM"]);
await names.removeDuplicates();
await names.renameColumns({
DADGUID_ADIDUGD: "DGUID",
CMANAME_RMRNOM: "CMA",
});
await census.join(names);
const disseminationAreas = sdb.newTable("disseminationAreas");
await disseminationAreas.loadGeoData(
"sda/data/lda_000b21a_e_simplified.shp.zip",
);
await disseminationAreas.logProjections()
await disseminationAreas.logTable();
});
return census;
}
Nous n’avons aucun problème à charger les données géospatiales. Nous pouvons voir les 57 932 aires de diffusion sous forme de lignes avec leurs propriétés et leurs géométries.
Mais la projection proj=lcc avec ses units=m pose problème. Statistique Canada utilise la projection conforme conique de Lambert avec des coordonnées en mètres. Pour que de nombreuses méthodes de SDA fonctionnent correctement, nous avons besoin des coordonnées avec la projection WGS84 utilisant la latitude et la longitude.
Mais ne vous inquiétez pas, SDA gère cela pour vous. Il vous suffit de passer l’option { toWGS84: true } pour convertir vos données géospatiales au bon format.
Pendant qu’on y est, sélectionnons uniquement les colonnes qui nous intéressent :
DGUID, qui est l’ID unique pour les aires de diffusion. Nous l’utiliserons pour joindre les géométries aux données du recensement.geom, qui contient les géométries.
Et joignons la table disseminationAreas à la table census ! Comme nous avons un DGUID dans chaque table, SDA l’utilisera pour faire correspondre les données du recensement des aires de diffusion avec les bonnes frontières.
import { SimpleDB } from "@nshiab/simple-data-analysis";
export default async function crunchData(sdb: SimpleDB) {
const census = sdb.newTable("census");
await census.cache(async () => {
await census.loadData("sda/data/98-401-X2021006_eng_CSV/*_utf8.csv", {
strict: false,
limit: 1_000_000,
});
await census.keep({
GEO_LEVEL: "Dissemination area",
CHARACTERISTIC_ID: [243], // Median total income of household in 2020 ($)
});
await census.selectColumns([
"DGUID",
"GEO_NAME",
"C1_COUNT_TOTAL",
]);
await census.renameColumns({ C1_COUNT_TOTAL: "medianIncome" });
const names = sdb.newTable("names");
await names.loadData("sda/data/2021_92-151_X_utf8.csv", { strict: false });
await names.keep({
CMATYPE_RMRGENRE: "B",
});
await names.selectColumns(["DADGUID_ADIDUGD", "CMANAME_RMRNOM"]);
await names.removeDuplicates();
await names.renameColumns({
DADGUID_ADIDUGD: "DGUID",
CMANAME_RMRNOM: "CMA",
});
await census.join(names);
const disseminationAreas = sdb.newTable("disseminationAreas");
await disseminationAreas.loadGeoData(
"sda/data/lda_000b21a_e_simplified.shp.zip",
{ toWGS84: true },
);
await disseminationAreas.selectColumns(["DGUID", "geom"]);
await census.join(disseminationAreas);
});
return census;
}
Nos données sont enfin complètes ! Nous avons nos aires de diffusion avec leur revenu total médian des ménages, le nom de leur région métropolitaine et leurs frontières !
Nous pouvons supprimer l’option limit à la ligne 9 et sélectionner uniquement les trois colonnes que nous utiliserons par la suite. Nous pouvons également supprimer les lignes avec des valeurs manquantes.
Traitons toutes les données maintenant !
import { SimpleDB } from "@nshiab/simple-data-analysis";
export default async function crunchData(sdb: SimpleDB) {
const census = sdb.newTable("census");
await census.cache(async () => {
await census.loadData("sda/data/98-401-X2021006_eng_CSV/*_utf8.csv", {
strict: false,
});
await census.keep({
GEO_LEVEL: "Dissemination area",
CHARACTERISTIC_ID: [243], // Median total income of household in 2020 ($)
});
await census.selectColumns([
"DGUID",
"GEO_NAME",
"C1_COUNT_TOTAL",
]);
await census.renameColumns({ C1_COUNT_TOTAL: "medianIncome" });
const names = sdb.newTable("names");
await names.loadData("sda/data/2021_92-151_X_utf8.csv", { strict: false });
await names.keep({
CMATYPE_RMRGENRE: "B",
});
await names.selectColumns(["DADGUID_ADIDUGD", "CMANAME_RMRNOM"]);
await names.removeDuplicates();
await names.renameColumns({
DADGUID_ADIDUGD: "DGUID",
CMANAME_RMRNOM: "CMA",
});
await census.join(names);
const disseminationAreas = sdb.newTable("disseminationAreas");
await disseminationAreas.loadGeoData(
"sda/data/lda_000b21a_e_simplified.shp.zip",
{ toWGS84: true },
);
await disseminationAreas.selectColumns(["DGUID", "geom"]);
await census.join(disseminationAreas);
await census.selectColumns(["medianIncome", "CMA", "geom"]);
await census.removeMissing();
});
return census;
}
Nous avons maintenant nos données pour environ 37 000 aires de diffusion situées dans des régions métropolitaines.
Et comme tout ce code est dans la méthode cache, il ne s’exécutera qu’une seule fois, ce qui nous permettra de travailler rapidement sur les prochaines étapes ! Comme indiqué ci-dessus, lors de la première exécution, le code a mis 1 min 31 s à s’exécuter sur mon ordinateur. Mais lors de la seconde, il n’a fallu que 97 ms. 😏

La structuration, le formatage, le filtrage et le nettoyage des données sont souvent les étapes les plus longues dans l’analyse et la visualisation de données. 🫠 Mais il est également extrêmement important de bien les faire pour éviter les erreurs dans votre analyse et vos visualisations.
Prenez toujours le temps de lire la documentation des données. Cela peut sembler une perte de temps au début, mais cela vous fera en réalité gagner beaucoup de temps par la suite. J’ai déjà vécu ça. Faites-moi confiance. 🫣
Répondre à la question
Variation par rapport à la médiane
La question à laquelle nous voulons répondre est :
- Pour chaque région métropolitaine canadienne, quelles sont les aires de diffusion dont le revenu des ménages est supérieur ou inférieur à la médiane ?
Nous devons donc trouver le revenu total médian des ménages pour chaque région métropolitaine. C’est facile à faire avec la méthode summarize.
Notez que nous pouvons maintenant travailler en dehors de la méthode cache. Les données étant nettoyées et filtrées, cela devient beaucoup plus léger à traiter.
import { SimpleDB } from "@nshiab/simple-data-analysis";
export default async function crunchData(sdb: SimpleDB) {
const census = sdb.newTable("census");
await census.cache(async () => {
await census.loadData("sda/data/98-401-X2021006_eng_CSV/*_utf8.csv", {
strict: false,
});
await census.keep({
GEO_LEVEL: "Dissemination area",
CHARACTERISTIC_ID: [243], // Median total income of household in 2020 ($)
});
await census.selectColumns([
"DGUID",
"GEO_NAME",
"C1_COUNT_TOTAL",
]);
await census.renameColumns({ C1_COUNT_TOTAL: "medianIncome" });
const names = sdb.newTable("names");
await names.loadData("sda/data/2021_92-151_X_utf8.csv", { strict: false });
await names.keep({
CMATYPE_RMRGENRE: "B",
});
await names.selectColumns(["DADGUID_ADIDUGD", "CMANAME_RMRNOM"]);
await names.removeDuplicates();
await names.renameColumns({
DADGUID_ADIDUGD: "DGUID",
CMANAME_RMRNOM: "CMA",
});
await census.join(names);
const disseminationAreas = sdb.newTable("disseminationAreas");
await disseminationAreas.loadGeoData(
"sda/data/lda_000b21a_e_simplified.shp.zip",
{ toWGS84: true },
);
await disseminationAreas.selectColumns(["DGUID", "geom"]);
await census.join(disseminationAreas);
await census.selectColumns(["medianIncome", "CMA", "geom"]);
await census.removeMissing();
});
const medians = await census.summarize({
values: "medianIncome",
categories: "CMA",
summaries: "median",
outputTable: "medians",
});
await medians.logTable();
return census;
}
Maintenant que nous avons la médiane pour chaque CMA dans la table medians, nous pouvons joindre la table medians à la table census. Comme les deux tables ont la colonne CMA, SDA pourra facilement faire correspondre les lignes. Par commodité, nous pouvons supprimer la colonne value de medians avant de faire la jointure.
Nous pouvons maintenant ajouter une nouvelle colonne varPerc avec la variation en pourcentage par rapport à la médiane pour chaque aire de diffusion. Nous pouvons également arrondir les valeurs. C’est ce que nous utiliserons pour colorer nos cartes.
import { SimpleDB } from "@nshiab/simple-data-analysis";
export default async function crunchData(sdb: SimpleDB) {
const census = sdb.newTable("census");
await census.cache(async () => {
await census.loadData("sda/data/98-401-X2021006_eng_CSV/*_utf8.csv", {
strict: false,
});
await census.keep({
GEO_LEVEL: "Dissemination area",
CHARACTERISTIC_ID: [243], // Median total income of household in 2020 ($)
});
await census.selectColumns([
"DGUID",
"GEO_NAME",
"C1_COUNT_TOTAL",
]);
await census.renameColumns({ C1_COUNT_TOTAL: "medianIncome" });
const names = sdb.newTable("names");
await names.loadData("sda/data/2021_92-151_X_utf8.csv", { strict: false });
await names.keep({
CMATYPE_RMRGENRE: "B",
});
await names.selectColumns(["DADGUID_ADIDUGD", "CMANAME_RMRNOM"]);
await names.removeDuplicates();
await names.renameColumns({
DADGUID_ADIDUGD: "DGUID",
CMANAME_RMRNOM: "CMA",
});
await census.join(names);
const disseminationAreas = sdb.newTable("disseminationAreas");
await disseminationAreas.loadGeoData(
"sda/data/lda_000b21a_e_simplified.shp.zip",
{ toWGS84: true },
);
await disseminationAreas.selectColumns(["DGUID", "geom"]);
await census.join(disseminationAreas);
await census.selectColumns(["medianIncome", "CMA", "geom"]);
await census.removeMissing();
});
const medians = await census.summarize({
values: "medianIncome",
categories: "CMA",
summaries: "median",
outputTable: "medians",
});
await medians.removeColumns("value");
await census.join(medians);
await census.addColumn(
"varPerc",
"number",
`(medianIncome - median) / median * 100`,
);
await census.round("varPerc");
return census;
}
Nous avons maintenant la réponse à notre question : la variation par rapport à la médiane dans chaque aire de diffusion pour toutes les régions métropolitaines.
Il est temps de visualiser tout ça !
Création des cartes
Pour garder notre code organisé et pour rester sain d’esprit, créons un nouveau fichier visualizeData.ts dans le dossier helpers.
La nouvelle fonction aura besoin de la table census et, pour l’instant, elle se contentera de l’afficher dans la console.
import { SimpleTable } from "@nshiab/simple-data-analysis";
export default async function visualizeData(census: SimpleTable) {
await census.logTable();
}Et mettons à jour main.ts pour appeler cette nouvelle fonction.
import { SimpleDB } from "@nshiab/simple-data-analysis";
import crunchData from "./helpers/crunchData.ts";
import visualizeData from "./helpers/visualizeData.ts";
const sdb = new SimpleDB({ cacheVerbose: true });
const census = await crunchData(sdb);
await visualizeData(census);
await sdb.done();Nous voulons dessiner une carte pour chaque région métropolitaine, alors commençons par récupérer toutes les régions métropolitaines uniques dans nos données.
Ensuite, nous pouvons les parcourir dans une boucle, cloner la table census et ne garder que les lignes correspondant à la bonne CMA.
Comme vous pouvez le voir dans la capture d’écran ci-dessous, lorsque vous ne spécifiez pas de nom pour les tables, SDA les nomme automatiquement table0, table1, etc. Ici, nous voyons que la dernière table est table42, ce qui signifie que nous parcourons 43 régions métropolitaines.
Pour connaître le nombre de régions métropolitaines, vous pouvez également vérifier la propriété .length de allCMAs, puisque getUniques renvoie toutes les valeurs uniques d’une colonne sous forme de liste.
import { SimpleTable } from "@nshiab/simple-data-analysis";
export default async function visualizeData(census: SimpleTable) {
const allCMAs = await census.getUniques("CMA");
for (const CMA of allCMAs) {
const tableCMA = await census.cloneTable();
await tableCMA.keep({ CMA });
await tableCMA.logTable();
}
}
Comme la table census possède une colonne CMA et que la boucle utilise également la variable CMA, nous pouvons écrire { CMA } comme raccourci pour { CMA: CMA }.
Nous pouvons maintenant créer une fonction pour dessiner nos cartes. Lorsque nous avons tout configuré avec setup-sda, nous avons automatiquement installé Plot. Cette puissante librairie de visualisation de données fonctionne très bien avec SDA et c’est ce que nous allons utiliser pour dessiner nos cartes.
Comme c’est la même fonction pour dessiner toutes les cartes, nous pouvons la créer en dehors de la boucle. Cette fonction attendra les données au format GeoJSON, avec une liste de features contenant des propriétés. Pour commencer, dessinons les polygones des aires de diffusion avec le marqueur geo et colorons le fill et le stroke avec les valeurs calculées dans la colonne varPerc.
Dans la boucle, nous pouvons passer cette fonction à la méthode writeMap, qui lui transmettra les données de la table au format GeoJSON. Nous devons également spécifier l’emplacement où nous voulons enregistrer la carte, et nous utilisons le nom de la région métropolitaine pour créer des fichiers uniques dans le dossier output.
Comme nous sommes encore en phase d’exploration pour la création des cartes, limitons la boucle pour ne travailler que sur la première région métropolitaine pour l’instant. Cela nous permettra d’itérer plus rapidement et d’améliorer notre visualisation des données.
import { SimpleTable } from "@nshiab/simple-data-analysis";
import { geo, plot } from "@observablehq/plot";
export default async function visualizeData(census: SimpleTable) {
const allCMAs = await census.getUniques("CMA");
function drawMap(
data: { features: { properties: { [key: string]: unknown } }[] },
) {
return plot({
marks: [
geo(data, { fill: "varPerc", stroke: "varPearc" }),
],
});
}
for (const CMA of allCMAs) {
const tableCMA = await census.cloneTable();
await tableCMA.keep({ CMA });
await tableCMA.writeMap(drawMap, `./sda/output/${CMA}.png`);
break;
}
}
C’est moche, mais ça fonctionne !
Nous pouvons maintenant ajouter un titre, un sous-titre et une légende. Nous pouvons également utiliser une échelle divergente pour les couleurs et restreindre le domaine de -100 % à +100 %. Nous pouvons aussi ajuster la projection. Si vous voulez en savoir plus sur ces personnalisations, consultez la leçon Visualiser des données.
Une chose que vous vous demandez peut-être est pourquoi nous utilisons data.features[0].properties.CMA pour le titre.
Lorsque cette fonction sera exécutée, elle ne connaîtra pas la variable CMA. Nous devons donc récupérer le nom de la région métropolitaine directement à partir des données. Comme nous utilisons writeMap, SDA transmet les données sous forme de GeoJSON à cette fonction. Dans les features GeoJSON, les données sont stockées dans l’objet properties. Nous récupérons donc le nom de la région métropolitaine en prenant le premier feature et en trouvant le nom CMA dans ses propriétés.
import { SimpleTable } from "@nshiab/simple-data-analysis";
import { geo, plot } from "@observablehq/plot";
export default async function visualizeData(census: SimpleTable) {
const allCMAs = await census.getUniques("CMA");
function drawMap(
data: { features: { properties: { [key: string]: unknown } }[] },
) {
return plot({
title: data.features[0].properties.CMA,
subtitle:
"Variation from the median household total income at the dissemination area level.",
caption: "2021 Census, Statistics Canada",
inset: 10,
projection: {
type: "mercator",
domain: data,
},
color: {
legend: true,
type: "diverging",
domain: [-100, 100],
label: null,
tickFormat: (d) => {
if (d > 0) {
return `+${d}%`;
} else {
return `${d}%`;
}
},
},
marks: [
geo(data, { fill: "varPerc", stroke: "varPerc" }),
],
});
}
for (const CMA of allCMAs) {
const tableCMA = await census.cloneTable();
await tableCMA.keep({ CMA });
await tableCMA.writeMap(drawMap, `./sda/output/${CMA}.png`);
break;
}
}
Ça a bien meilleure allure.
Une dernière chose que j’aime faire sur mes cartes est d’ajouter un contour.
Dans la boucle, nous pouvons cloner la tableCMA et fusionner toutes les géométries des aires de diffusion en utilisant la méthode aggregateGeo. Comme cela peut être assez coûteux en termes de calcul lorsqu’il y a beaucoup d’aires de diffusion, nous mettons le résultat en cache.
Nous pouvons ensuite insérer cette géométrie nouvellement créée dans la tableCMA.
Dans la fonction drawMap, nous pouvons ajouter un nouveau marqueur geo pour dessiner le contour. Mais nous devons filtrer sur le varPerc pour nous assurer de ne dessiner que le contour et non toutes les aires de diffusion à nouveau.
import { SimpleTable } from "@nshiab/simple-data-analysis";
import { geo, plot } from "@observablehq/plot";
export default async function visualizeData(census: SimpleTable) {
const allCMAs = await census.getUniques("CMA");
function drawMap(
data: { features: { properties: { [key: string]: unknown } }[] },
) {
return plot({
title: data.features[0].properties.CMA,
subtitle:
"Variation from the median household total income at the dissemination area level.",
caption: "2021 Census, Statistics Canada",
inset: 10,
projection: {
type: "mercator",
domain: data,
},
color: {
legend: true,
type: "diverging",
domain: [-100, 100],
label: null,
tickFormat: (d) => {
if (d > 0) {
return `+${d}%`;
} else {
return `${d}%`;
}
},
},
marks: [
geo(
data.features.filter((d) => typeof d.properties.varPerc === "number"),
{ fill: "varPerc", stroke: "varPerc" },
),
geo(data.features.filter((d) => d.properties.varPerc === null), {
stroke: "black",
opacity: 0.5,
}),
],
});
}
for (const CMA of allCMAs) {
const tableCMA = await census.cloneTable();
await tableCMA.keep({ CMA });
const outline = await tableCMA.cloneTable();
await outline.cache(async () => {
await outline.aggregateGeo("union");
});
await tableCMA.insertTables(outline);
await tableCMA.writeMap(drawMap, `./sda/output/${CMA}.png`);
break;
}
}
La différence est subtile, mais il est important de voir les trous dans la géométrie de la région métropolitaine.
Maintenant que nous sommes satisfaits de l’apparence de notre carte, il est temps de supprimer l’instruction break à la ligne 57 ! Créons 43 cartes ! Exécutez tout le code !
Si vous examinez les cartes après avoir exécuté votre code, vous remarquerez quelques problèmes.

Tout d’abord, vous pouvez voir que certains dossiers ont été créés pour certaines régions métropolitaines dans le dossier output. C’est parce que certains noms contiennent le caractère / ! Nous devons remplacer ce caractère par autre chose avant de le transmettre à writeMap.
Nous pouvons mettre à jour visualizeData.ts pour corriger cela.
import { SimpleTable } from "@nshiab/simple-data-analysis";
import { geo, plot } from "@observablehq/plot";
export default async function visualizeData(census: SimpleTable) {
const allCMAs = await census.getUniques("CMA");
function drawMap(
data: { features: { properties: { [key: string]: unknown } }[] },
) {
return plot({
title: data.features[0].properties.CMA,
subtitle:
"Variation from the median household total income at the dissemination area level.",
caption: "2021 Census, Statistics Canada",
inset: 10,
projection: {
type: "mercator",
domain: data,
},
color: {
legend: true,
type: "diverging",
domain: [-100, 100],
label: null,
tickFormat: (d) => {
if (d > 0) {
return `+${d}%`;
} else {
return `${d}%`;
}
},
},
marks: [
geo(
data.features.filter((d) => typeof d.properties.varPerc === "number"),
{ fill: "varPerc", stroke: "varPerc" },
),
geo(data.features.filter((d) => d.properties.varPerc === null), {
stroke: "black",
opacity: 0.5,
}),
],
});
}
for (const CMA of allCMAs) {
const tableCMA = await census.cloneTable();
await tableCMA.keep({ CMA });
const outline = await tableCMA.cloneTable();
await outline.cache(async () => {
await outline.aggregateGeo("union");
});
await tableCMA.insertTables(outline);
await tableCMA.writeMap(
drawMap,
`./sda/output/${(CMA as string).replaceAll("/", "-")}.png`,
);
}
}Nous pouvons également constater que le contour de certaines villes n’est pas correct et que la carte de Montréal n’est qu’un énorme polygone. Cela se produit généralement lorsque certaines géométries sont invalides. La simplification crée souvent des géométries invalides. Heureusement, nous pouvons utiliser la méthode fixGeo pour résoudre ce problème !
Nous pouvons mettre à jour crunchData.ts, dans la méthode cache, pour corriger les géométries après le chargement des données géospatiales.
import { SimpleDB } from "@nshiab/simple-data-analysis";
export default async function crunchData(sdb: SimpleDB) {
const census = sdb.newTable("census");
await census.cache(async () => {
await census.loadData("sda/data/98-401-X2021006_eng_CSV/*_utf8.csv", {
strict: false,
});
await census.keep({
GEO_LEVEL: "Dissemination area",
CHARACTERISTIC_ID: [243], // Median total income of household in 2020 ($)
});
await census.selectColumns([
"DGUID",
"GEO_NAME",
"C1_COUNT_TOTAL",
]);
await census.renameColumns({ C1_COUNT_TOTAL: "medianIncome" });
const names = sdb.newTable("names");
await names.loadData("sda/data/2021_92-151_X_utf8.csv", { strict: false });
await names.keep({
CMATYPE_RMRGENRE: "B",
});
await names.selectColumns(["DADGUID_ADIDUGD", "CMANAME_RMRNOM"]);
await names.removeDuplicates();
await names.renameColumns({
DADGUID_ADIDUGD: "DGUID",
CMANAME_RMRNOM: "CMA",
});
await census.join(names);
const disseminationAreas = sdb.newTable("disseminationAreas");
await disseminationAreas.loadGeoData(
"sda/data/lda_000b21a_e_simplified.shp.zip",
{ toWGS84: true },
);
await disseminationAreas.fixGeo();
await disseminationAreas.selectColumns(["DGUID", "geom"]);
await census.join(disseminationAreas);
await census.selectColumns(["medianIncome", "CMA", "geom"]);
await census.removeMissing();
});
const medians = await census.summarize({
values: "medianIncome",
categories: "CMA",
summaries: "median",
outputTable: "medians",
});
await medians.removeColumns("value");
await census.join(medians);
await census.addColumn(
"varPerc",
"number",
`(medianIncome - median) / median * 100`,
);
await census.round("varPerc");
return census;
}Arrêtez de surveiller main.ts (CTRL + C dans votre terminal) et supprimez .temp et .sda-cache manuellement ou en exécutant deno task clean. Supprimez également tout le contenu du dossier output.
Et relançons tout depuis le début !

Tout fonctionne parfaitement et tous nos problèmes ont disparu. 😁
Sur mon ordinateur, notre code a pu traiter toutes les données et dessiner toutes les cartes en 2 minutes et 46 secondes. Mais grâce à notre système de mise en cache astucieux, si je veux ajuster l’apparence des cartes, cela prend seulement 32 secondes pour réécrire les 43 cartes.
Au fait, ici, nous enregistrons nos cartes sous forme d’images, mais si vous voulez des vecteurs pour les modifier dans Illustrator ou d’autres outils de conception, il vous suffit de remplacer .png par .svg dans writeMap.
Conclusion
Que de chemin parcouru ! Traiter de grands ensembles de données avec plusieurs tables stockant des données tabulaires et géospatiales n’est pas une tâche facile.
Mais j’espère que cet exemple concret vous a montré comment vous pouvez couper au travers de gigaoctets de données comme dans du beurre avec SDA. 🧈
Amusez-vous bien avec votre prochain projet de données et n’hésitez pas à me contacter si vous souhaitez partager ce que vous créez avec SDA ou si vous avez des questions ! 😊